Обнаружив ошибку на странице, выделите ее и нажмите Ctrl + Enter
Каталогизация литературы - актуальная проблема, особенно для людей, которые занимаются научной, инженерной и преподавательской работой. Данная тема рассматривалась на разных форумах, например, http://www.chemport.ru/forum/viewtopic.php?f=35&t=11260, http://forum.ru-board.com/topic.cgi?forum=5&topic=7321&start=160 и других. Вопрос можно разделить на две части - собственно составление каталогов и текстовый поиск.
Существуют две возможности текстового поиска - с предварительной индексацией и без. По ходу следует отметить принципиальную возможность текстового поиска только в файлах с распознанным текстом. По стандарту текстовый слой в *.djvu файлах должен быть в UTF-8, но иногда он встречается в кодировке Windows-1251 (кодовая страница, далее я буду для краткости называть ее ANSI, хотя это несколько разные понятия).
С файлами формата .pdf, имеющими текст на кириллице, все бывает сложнее. Кодировки и шрифты используют "кто на что горазд". Возможность поиска для каждого файла следует проверить. Простой способ - выделить кусок текста и скопировать его в блокнот. Если текст не копируется, возможно, файл защищен от копирования. Снять защиту можно утилитой A-PDF Password Security http://ru.software-free-download.net/archives/1084. Хотя она коммерческая, но опция снятия пароля работает бесплатно.
Если скопированный текст не читается, возможно, поможет обработка исходного файла утилитой pdf-recode. http://forum.rudtp.ru/showthread.php?t=36974&page=1&pp=20
Рассмотрим поиск с предварительной индексацией. Кроме коммерческой программы Архивариус 3000 существуют бесплатные: штатная служба индексирования в Windows и Windows Searсh http://www.microsoft.com/downloads/details.aspx?FamilyID=55c18cb3-c916-4298-aba3-5b98904f7cda&DisplayLang=ru от MS, поисковики от Яндекса и Google для поиска "внутри компьютера", но все они требуют установки фильтров (Ifilter), которые по-существу являются извлекателями текста из файлов разного формата и часто требуют установки дополнительных компонентов, таких как NET Framework.
Все дальнейшее описание связано с применением файлового менеджера Total Commander (далее в тексте TC), у меня установлена версия 7.50а. Если на панели инструментов (тулбаре) отсутствует кнопка "Поиск файлов" в виде бинокля, ее лучше установить. Кликнуть правой кнопкой по свободному месту тулбара, выбрать "Изменить" и "Добавить", заполнить поля в диалоговом окне:
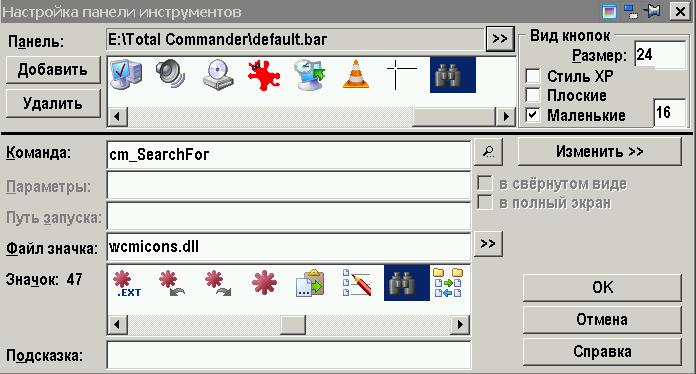
1. Поиск с индексированием вручную.
1.1. Предлагаю для рассмотрения вариант ручного индексирования файлов с минимальной установкой дополнительных компонентов.
Штатными средствами WinDjView извлекает текст из *.djvu в кодировку ANSI, но по одному файлу. Используя конвертер djvutxt.exe из комплекта DjVuLibre можно это делать групповым образом.
Здесь и далее под конвертером понимается комплект из файла *.exe и необходимых для его работы компонентов. В случае *.djvu достаточно пяти файлов:
djvutxt.exe
libdjvulibre.dll
libjpeg.dll
Microsoft.VC90.CRT.manifest
msvcr90.dll
Надо один раз создать *.bat файл, например, на 99 файлов, использовать его можно многократно. Содержание .bat файла может быть, например, таким:
djvutxt 01.djvu 01
djvutxt 02.djvu 02
...
djvutxt 99.djvu 99
Дальнейшие действия с помощью TC напоминают танец с бубном.
Надо создать временную папку, скопировать туда индексируемые .djvu файлы, конвертер и созданный .bat файл. Групповым переименованием поменять названия исходных файлов на номера, начиная с 01.djvu. Затем запустить .bat файл. После того, как будут получены все выходные текстовые файлы без расширений, надо запустить вторую копию коммандера и в ней удалить из временной папки все исходные *.djvu, а полученным текстовым файлам групповым переименованием присвоить расширения .djvu. После этого перейти в первое окно ТС и произвести откат группового переименования. В результате имеем текстовые файлы с именами исходных файлов и расширениями .djvu. Остается заменить расширения на .txt.
1.2. Существует и более легкий способ группового извлечения текстов - при помощи плагина executor http://wincmd.ru/plugring/executor.html, с моими настройками - http://chemistry-chemists.com/forum/download/file.php?id=5134
Для этого надо скопировать комплект файлов соответствующего конвертера непосредственно в папку с плагином (из дальнейшего станет ясно, почему именно так). Файл настройки плагина должен быть соответствующим образом сконфигурирован. В настройках архиваторных плагинов выполнить ассоциацию требуемых типов файлов с плагином. Теперь достаточно выделить файлы на файловой панели ТС, нажать кнопку "Распаковать файлы" на панели инструментов и после соответствующего диалога начнется извлечение в текстовые файлы с исходными именами в папку, открытую на неактивной файловой панели.
К сожалению, текущая версия плагина имеет баг: формируемые им команды ограничены 256 символами, куда входят имена входного и выходного файлов и конвертера с абсолютными путями, если не уложиться - имя выходного будет обрезано. Поэтому, рекомендуется создать папку с коротким путем, например C:/Tmp, и в нее скопировать исходные файлы, выходные файлы могут создаваться в ней же. Из этих же соображений удобнее, когда ТС установлен в папку Wincmd в корневой директории диска.
Имеется альтернативный плагин того же назначения http://wincmd.ru/plugring/ctconv.html, но у него другие недостатки: требует наличия в папке System32 библиотек msvcr71.dll и msvcp71.dll, которых нет в исходном дистрибутиве WinXP, они ставятся с какими-то обновлениями. Но у меня получилось их просто скачать и "запихнуть" в указанную папку. С настройками этого плагина под конвертеры я не разобрался.
Для других форматов есть соответствующие конвертеры, подробнее - во второй части, операции с ними аналогичны описанным для *.djvu.
По умолчанию ТС ищет текст в ANSI кодировке (можно отметить другую). Для удобства (однозаходного поиска) целесообразно все текстовые файлы привести к этой кодировке. Для этого можно перекодировать групповым образом, используя текстовый редактор Akelpad http://chemistry-chemists.com/forum/viewtopic.php?p=14118#p14118. Необходимо выделить нужные файлы и перетащить их в окно этого блокнота. (Сам я для этой операции пользуюсь утилитой http://wincmd.ru/plugring/ChoiceEditor_patched.html ). Далее в меню "Файл" нажать "Сохранить все как" и выбрать кодировку. Аналогично - для других типов файлов, которым имеет смысл заменить кодировку текста. Теперь рассмотрим собственно сам процесс поиска. Например, мой архив журнала "Химия и Жизнь" структурирован таким образом, что в папке с номерами в .djvu или .pdf за год лежат так же и файлы .txt извлеченных текстов с теми же именами. Выбираю нужную папку и вызываю диалоговое окно поиска. В поле "Искать файлы" задаем маску *.txt , отмечаем "С текстом" , набираем искомое слово. На втором пентиуме поиск в полутысяче файлов занимает меньше минуты. Для уточнения поиска задаем команды: "Файлы - на панель", "Инвертировать выделение (Выделить все)". Теперь можно в найденном искать файлы с другим словом. Далее открываем просмотр и в меню "Правка" выбираем поиск слова уже внутри файла. Либо "Файлы - на панель", открыть соответствующий найденному *.djvu или *.pdf и продолжить поиск слова внутри файла средствами вьювера.
Безусловно, поиск с предварительным индексированием, т.е. среди текстовых файлов происходит во много раз быстрее, однако требует вышеописанной подготовки и дополнительного места. Грубо говоря, .txt могут занимать около десятой части от веса индексируемых *.djvu и *.pdf. Однако, для *.htm(l), *.doc, *.docx, *.fb2, *.chm индексирование я считаю нецелесообразным. *.Chm и *.docx вообще сжатые форматы и если в этих файлах мало рисунков, может оказаться, что извлеченный текст будет весить больше исходного файла.
2. Поиск без предварительного индексирования.
2.1 Поиск без плагинов.
В файлах *.txt, *.htm(l), *.fb2 текст можно найти без предварительной индексации, однако исходная кодировка у них может быть разная, это легко проверяется в окне просмотра (F3) подбором кодировки. Чтобы не искать в несколько приемов, желательно все файлы этих форматов привести к единой кодировке, как описано выше.
Например, для удобства поиска текста в файлах *.htm(l). Выделив папку, вызываем окно поиска, в поле "Искать файлы" вводим маску *.htm, ставим галочку напротив пункта "С текстом", вводим "charset=utf-8" (без кавычек), включаем поиск:
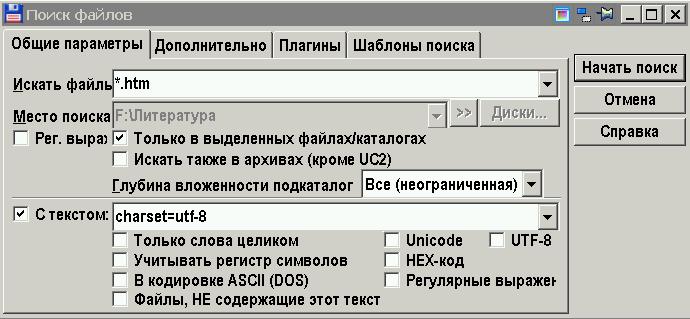
Пример: поиск слова "графлекс" в текстовых файлах, извлеченных из 538 номеров журнала "Химия и Жизнь" на компьютере с процессором 1,4 ГГц идет 10 секунд. Поиск этого же слова в исходных *.djvu и *.pdf занимает 20 минут с помощью плагина TextSearch, т.е. без использования предварительного индексирования.
2.2 Использование плагина TextSearch.
Настроенный плагин: http://chemistry-chemists.com/forum/download/file.php?id=5133
Плагин извлекает текст во временную папку "на лету". Используются при этом те же конвертеры.
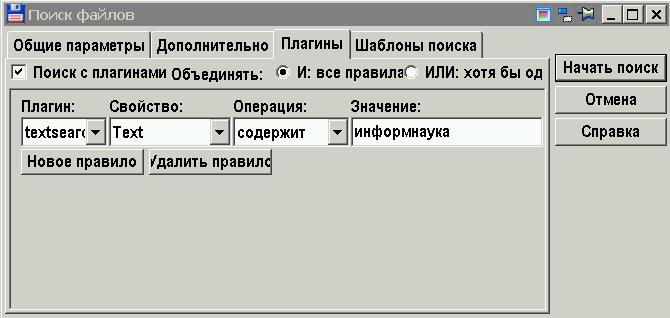
Для просмотра в виде текста используется плагин wlx_multilister. Плагин соответствующим образом настроен (http://chemistry-chemists.com/forum/download/file.php?id=5135). В меню просмотрщика "Вид" выбран пункт "Графика / Мультимедиа / LS-плагины". По тексту (уже внутри файла) возможен поиск. Через плагин можно искать текст в файлах и тех типов, для которых применение плагина необязательно. Это дает возможность поиска за один проход в файлах разных типов и кодировок.
Рассмотрим особенности поиска для каждого типа файла и конвертера.
В *.txt плагин находит текст в кодировках ANSI, UTF8 и UTF16. При желании можно добавить или удалить кодировки редактированием файла настроек \Plugins\wdx\TextSearch\TextSearch.ini. Просмотр по F3, изменение кодировки через меню просмотрщика.
*.htm(l) аналогично. По умолчанию ищет в кодировках ANSI и UTF8. При просмотре в меню "Вид" выбрать "5 HTML (без показа тегов)". *.xml так же.
Файлы MS Office: *.doc, *.docx, *.xlsx, *.pptx: при поиске плагин использует конвертер xdoc2txt.exe из Японии http://www31.ocn.ne.jp/~h_ishida/ . Просмотр текста и поиск внутри файлов через плагин wlx_multilister с использованием того же конвертера.
*.rtf - то же самое. Просмотр и поиск внутри файла - средствами ТС, плагин не требуется, "Вид" - "Графика / Мультимедиа / LS-плагины"
Как уже говорилось выше, для *.djvu с OCR применен конвертер из комплекта DjVuLibre. http://djvu.sourceforge.net/ Просмотр текста выбранного файла и поиск внутри файла через плагин wlx_multilister с использованием того же конвертера.
Для *.pdf - gettext http://kryltech.com/freestf.htm#util
Этот конвертер извлекает текст даже из защищенных от этого файлов. Просмотр текста выбранного файла и поиск внутри файла через плагин wlx_multilister с использованием того же конвертера. Многие вьюверы тоже могут искать текст среди файлов *.pdf в заданной папке. Только надо учесть, что Foxit Reader некоторых версий имеет баг - поиск кириллицы чувствителен к регистру, поэтому лучше пользоваться PDF-XChange Viewer http://www.tracker-software.com/product/downloads
*.fb2 Поиск через конвертер fb2txt, взятый из комплекта FB2Any http://www.gribuser.ru/xml/fictionbook/2.0/software/
Если программа не установлена, для работы конвертера требуется зарегистрировать fb_2_txt.dll, запустив \Plugins\wdx\TextSearch\Conv\fb2txt\Зарегистрироватьfb_2_txt.dll.bat. Просмотр текста и поиск внутри файла возможен без плагина, в меню "Вид" выбрать "5 HTML (без показа тегов)", подобрать кодировку (обычно ANSI или UTF-8).
*.chm Поиск через конвертер FiltDump.exe от Microsoft, для работы требуется зарегистрировать библиотеку \Plugins\wdx\TextSearch\Conv\Chm\ЗарегистрироватьCHMIFilter.dll.bat. Просмотр файла и поиск внутри через плагин wlx_multilister, конвертер тот же. В случае файла большого размера (типа Новый справочник химика и технолога.chm) ТС может зависнуть, рекомендуется поиск без плагина TextSearch "в архивах" при установленном CHMDir. Поэтому, просьба к читателям: возможно, кому-нибудь удастся заставить работать другой конвертер chm2txt от Jamal Mazrui http://empowermentzone.com/chm2txt.zip
Для *.hlp, *.xls, *.ppt, *.pps использован конвертер gettext, для *.mht - XDoc.
В настройках плагинов прописаны пути к конвертерам для следующего расположения папок в ТС:
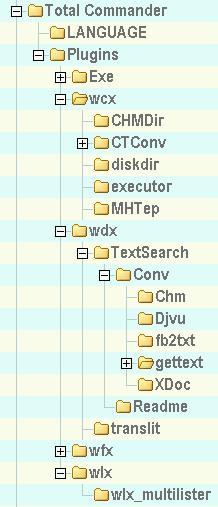
В окне просмотра через плагин wlx_multilister тоже есть кнопка поиска текста в файлах заданной папки. Этой возможностью пользоваться менее удобно. Зато это можно и без использования ТС.
На самом деле ТС является коммерческой программой и не у всех есть. Но существует бесплатная версия просмотрщика Universal Viewer http://www.uvviewsoft.com/index-ru.htm к которому можно установить тот же плагин wlx_multilister, однако настраивать его придется самостоятельно.
Скачать некоторые настроенные плагины можно на форуме <Ссылка> (см. также ссылки в тексте).